
Amazon, one of the largest global retailers, has a vast product range and customer base. Consequently, retailers worldwide seek strategies to tap into Amazon's market. One practical approach involves leveraging Amazon's bestseller charts. These charts highlight the products that have exhibited strong sales on Amazon, enabling retailers to utilize them as a reference for stocking their stores. Use Python to automate eCommerce data scraping and efficiently extract the required information.
This tutorial will demonstrate how to scrape Amazon's Best Seller lists using Python and BeautifulSoup. Our focus will be on the Computers & Accessories category from the Amazon Best Seller site. However, the same techniques are applicable to scrape data from any other category on the site. By scraping data from the Amazon Best Sellers list, you can gain insights into the current high-demand products, popular customer preferences, average price ranges for different product types, and more.
Scraping Process
We can employ web scraping tools and techniques to gather data on the most popular and highly rated products in the Computers & Accessories category on Amazon. Amazon is a dynamic website that customizes content for individual users based on their preferences and needs. Different users may see different content when visiting the same website. To extract information from a dynamic website using Python, we can utilize a headless browser like Selenium. Selenium allows us to programmatically navigate and interact with a website, simulating user actions without a graphical interface. By leveraging Selenium, we can automate the scraping process of dynamic content from Amazon.
Scraping Data From Amazon Best Seller Using Python And BeautifulSoup
To scrape Amazon Best Seller data from the Computers & Accessories category on the Amazon website, we can utilize Python packages such as BeautifulSoup and Selenium. To start web scraping using Selenium and Python, you must install both the Selenium package and a web driver. The web driver bridges Selenium and the web browser you want to control and access. Various web drivers, such as Chrome, Firefox, and Safari, are available for browsers. Once you have installed the Selenium package and the appropriate web driver, you can use them to scrape data from websites.
List Of Data Fields
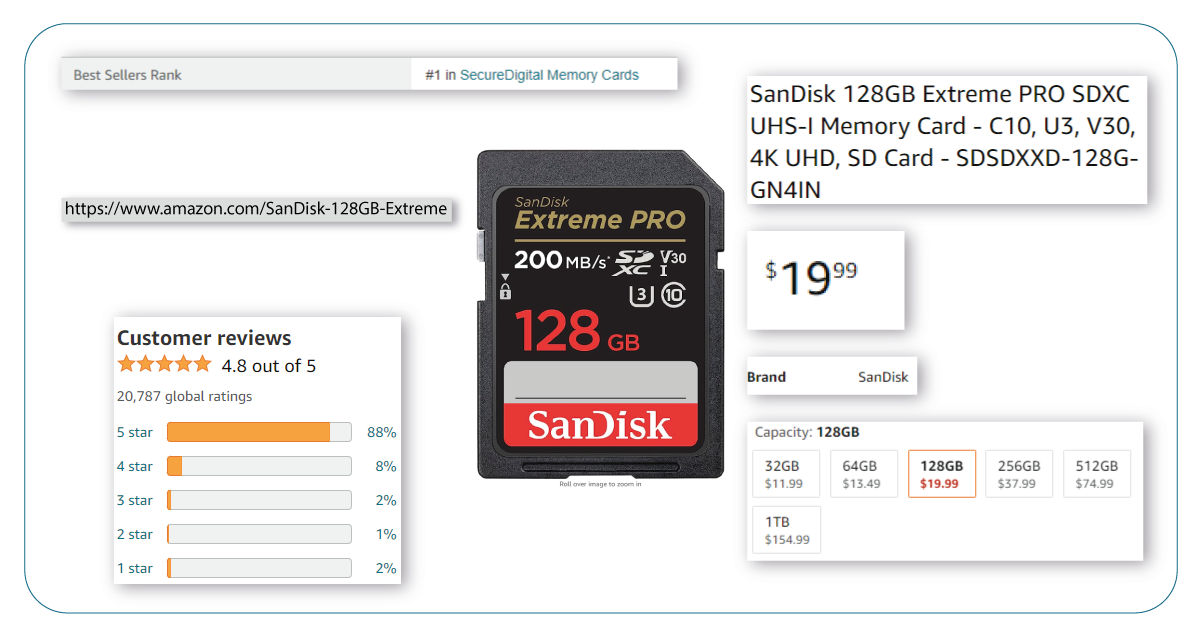
The following list of data fields is available for scraping Amazon Bestseller product data:
- Product URL: The link to the product.
- Ranking: The product's position within the overall list of best-selling products in the Computers & Accessories category on Amazon.
- Product Name: The name of the product.
- Brand: The brand name of the product.
- Price (in Dollars): The product is in US dollars.
- Number of Ratings: The total number of ratings the product has received.
- Star Rating: The average star rating of the product.
- Size: The size or dimensions of the product.
- Color: The color of the product.
- Hardware Interface
- Compatible Devices: Other devices that are compatible with the product.
- Connectivity TechnologyThe technology used for connecting the product.
- Connector Type: The type of connector used by the product.
- Data Transfer Rate: The rate at which the product transfers data.
- Mounting Type: The method used to attach the product.
- Special Features: Any additional features or functionalities of the product.
- Date First Available: When the product was initially made available on Amazon.
Importing Necessary Libraries
To initiate the process of web scraping Amazon Best Seller data, you'll need to import several libraries that facilitate website interaction and data extraction. Ensure that these libraries are installed and imported into your system. If there is no installation of libraries, you can use the pip command to install them. The following code helps import the necessary libraries for your script:

Here's a breakdown of the libraries and modules used in the scraping process:
- time library:A Python library that provides various time-related functions. It allows you to work with time-related operations such as getting the current time, converting between different time representations, and more.
- random library:It is a library that offers functions for creating arbitrary numbers and sequences. It allows you to generate random numbers, select random elements from a list, shuffle lists, and perform other random operations.
- pandas library:A powerful open-source library in Python for data manipulation and analysis. It provides data structures and tools for handling and analyzing numerical tables and time series data.
- BeautifulSoup module:Part of the bs4 library, BeautifulSoup is used for parsing and navigating HTML and XML files. It simplifies extracting data from these files by providing a more readable and efficient interface.
- Selenium library:Selenium is a popular tool for automating web browsers through programs. It allows you to perform browser automation tasks like clicking buttons, filling out forms, and navigating pages.
- webdriver module:The webdriver module is a part of the Selenium library and provides the functionality to interact with web browsers. It allows you to automate browser actions and control the browser programmatically.
- Extensions of the webdriver module:Selenium includes modules like Keys and By that offer additional classes and methods for interacting with web pages in more complex ways.
You can effectively scrape and extract information from the Amazon website by utilizing these libraries and modules.
To control a web browser and interact with the Amazon Best Sellers website using Selenium, you must create an instance of the web driver. The code snippet below demonstrates how to develop a Selenium browser example and specify the desired browser:
driver= webdriver.Crome(service=Service(CromeDriverManager().install()))Writing Functions
Using functions as reusable code snippets can significantly enhance the readability and maintainability of your code. By defining functions, you can organize your script into smaller, more manageable sections, each focusing on a specific task. This modular approach allows for easier understanding and maintenance of the codebase.
Moreover, creating functions enables code reuse, reducing redundancy and improving efficiency. Instead of duplicating code segments, you can call the function whenever needed. It promotes cleaner code and makes it easier to make changes or updates in a single place, propagating those changes across all the function calls.
Functions to Introduce Delays
It is advisable to introduce random delays between requests to avoid overwhelming a website with excessive requests. It is achievable by utilizing a function that pauses the execution of the following code segment for a random duration, typically between 3 and 10 seconds. Incorporating this function into the script adds variability to the timing of requests, making them less predictable and reducing the risk of detection, blocking, or throttling by the website. The function can be summarized as follows:

Functions to Get the Links and Product Rank
The function utilizes BeautifulSoup to parse the webpage's source code, using 'html.parser' as the chosen parser. It locates the first div element with the attribute "class" set to "p13n-desktop-grid", which contains the product sections on the page.
Next, it employs the find_all method to identify all div elements with the attribute "id" set to "gridItemRoot," representing individual products on the page.
For each product section, it locates all tags with the attribute 'tabindex' set to -1. It checks if the product link starts with 'https:.' If it does, the link directly appends to the product_links list. Otherwise, 'https://www.amazon.com' is appended before the product_link to form a valid URL, which is then available to the product_links list.
Additionally, the function extracts the rank of the product. It finds the span tag with the attribute "class" set to "zg-bdg-text" and retrieves the text content using the .text method. The rank appends to the ranking list.
Function To Extract Page Content
This function combines the usage of Selenium's WebDriver and BeautifulSoup to retrieve the HTML source code of the current webpage and subsequently parse it using BeautifulSoup with the 'html.parser' module.

Function To Extract Product Name
The function extract_product_name() employs the BeautifulSoup library to extract the name of a product from a webpage. Here's a summary of its functionality:
The function utilizes the find method to locate the first div element that matches the criteria of having an attribute "id" with the value "titleSection." This element is expected to contain the product name.
It retrieves all the text within the element using the text attribute and removes any leading or trailing whitespaces using the strip method.
The extracted product name is then available in the data frame's 'product name' column at the corresponding product index.
If the try block fails, indicating that the product name is unavailable, the function assigns the string 'Product name not available' to the 'product name' column of the data frame at the specific product index.

Function To Extract Brand Name
The extract_brand() function extracts a product's brand name using an Amazon data scraper. It first searches for an element with an "a" tag and an attribute "id" set to "bylineInfo," which contains the brand name. The text content of this element is retrieved, and the split(':') method is used to separate the brand name from any preceding text. Leading and trailing whitespaces are removed using the strip() method. The extracted brand name is in the 'brand' column of the product index in the data frame.
If the try block fails, indicating that the brand name is unavailable at the first location, the function searches for the brand name at an alternative location. It uses the find_all method to locate all elements that match the "tr" tag with an attribute "class" set to "a-spacing-small po-brand." The text content of these elements is retrieved, and the last element obtained from the split(' ') method is considered the brand name. This extracted brand name is then available in the 'brand' column of the product index in the data frame. If none of the try-except blocks fail, indicating that the brand data is unavailable, the function assigns the string 'Brand data not available' to the 'brand' column of the product index in the data frame.

Function To Extract Price
The extract_price() function extracts the price of a product. It begins with the find method to locate the first element that matches the span tag with the attribute "class" set to "a-price a-text-price size-medium apexPriceToPay." This element is expected to contain the price information of the product. The text content within this element is then retrieved using the text attribute.
For extracting the price value, the function applies the split('$') method on the obtained text result, separating the price from the currency symbol. The last element from this split result is considered the price value. Subsequently, the extracted price is assigned to the 'price(in dollars)' column of the data frame, corresponding to the product index. Suppose the try block fails to locate the price information, indicating the price is unavailable. In that case, the function assigns the string 'Price data not available' to the 'price(in a dollar)' column of the data frame, aligned with the specific product index.

Function To Extract Star Ratings
The provided code depicts a function called extract_star_rating() that is responsible for extracting the star rating of a product. Here's a summary of its functionality:
The function first initializes the variable star to None. It then iterates over two locations where the star rating is present. These locations are the CSS classes 'a-icon a-icon-star a-star-4-5' and 'a-icon a-icon-star a-star-5'.
Using the find_all() method of the BeautifulSoup object, the function searches for all elements with the current class name in the loop and assigns the results to the variable stars. It then iterates through the stars list and checks the text content of the first element. If it is not empty, the value is in the star variable, and the loop gets broken. This process is repeated for each potential location until a star rating is available.
After extracting the star rating, the function assigns its value to the 'star rating' column in the data frame at the specified product index.
Suppose an exception is raised during the process, indicating that the star rating is unavailable. In that case, the function assigns the string 'Star rating data not available' to the 'star rating' column in the data frame at the specified product index.

Fetching Product URLs
The code begins by initializing two empty lists, product_links, and ranking, which help store the links to the products and their rankings, respectively.
It then enters a for loop to iterate over the range of pages (1 to 2) with a product division. Within the loop, it defines the start_url variable, which contains the page URL for scraping. Using Selenium's get() method, it navigates to that URL.
Next, it calls the lazy_loading() function to handle lazy loading and ensure all products get loaded before extracting the links. Following that, it calls the fetch_product_links_and_ranks() function to extract the links of the products and their rankings from the page's HTML source code.
The code appends the product links and rankings to their respective lists. The product_links list will be used for navigating to individual product pages for data extraction, while the ranking list will store the ranking of the products.
Create a dictionary for initializing the data frame with column names as keys initialized as empty lists. This dictionary helps create a Pandas data frame named "data." Subsequently, the data frame is with the collected information by assigning the product_links list to the 'product_url' column and the ranking list to the 'ranking' column.

Extraction Of Necessary Features
Extraction of Necessary Features Extract specific details from each link in the 'product_url' column by calling the 'extract_content' function to obtain the page content. Afterward, it calls relevant functions for the fields to extract.

Saving The Data Into A CSV File
Finally, after generating the data frame, it is saved as a CSV file for later use or further analysis.

Insights From The Scraped Data
After analyzing the data, Amazon data scraping services develop several insights. The top 100 best-selling products on Amazon have prices ranging from $5 to $900. Categorizing them reveals that many of these products can be considered "Budget-friendly," with prices under $180. It suggests that affordability plays a crucial role in their popularity. The remaining products predominantly fall into the "Premium" category, with prices exceeding $720. Notably, many of these premium products are associated with well-known brands such as Apple and Acer, indicating that brand value contributes to their popularity. Interestingly, no products are classified as "Expensive" based on the given data.
Upon analyzing the star ratings of products on the bestseller list, the ratings range from 4.3 to 4.8. It indicates that all the products have ratings above the average level. Most of the products fall within the range of 4.4 to 4.6, suggesting high customer satisfaction and positive reviews for these popular products.
Conclusion: This blog showcases the utilization of Selenium and BeautifulSoup to scrape Amazon's Best Seller data in the Computers and Accessories category. It highlights various product features, including ranking, product name, brand name, star rating, price, connector type, and date first available. These insights help understand market trends, pricing strategies, and customer preferences. Automating the data collection process makes continuous monitoring of these trends feasible. It empowers businesses to make data-driven decisions, stay competitive, and gain valuable insights for informed decision-making.
As a leading product data scraping, we ensure that we maintain the highest standards of business ethics and lead all operations. We have multiple offices around the world to fulfill our customers' requirements.
At Product Data Scrape, we ensure that our Competitor Price Monitoring Services and Mobile App Data Scraping maintain the highest standards of business ethics and lead all operations. We have multiple offices around the world to fulfill our customers' requirements.
Know more :
https://www.productdatascrape.com/scrape-amazon-best-seller-lists-with-python-and-beautifulsoup.php













